

0. 为啥要学爬虫?
有无在网站上手动一张一张下载图片时感到麻烦?
可否好奇过网上所谓的 绘板活动
大家是如何参与其中的?
每每要获得一个网页中若干子网页的特定内容,是否感到烦恼?
希望保存一些视频、数据之类,但却无从下手?
爬虫会帮你解决上述的问题!
虽然计算机社活动的时间很短,所以讲不了太深的东西(主要我自己没有实力),只能介绍比较简单和常见的爬虫写法。
但我仍然希望大家能捞到点东西,有兴趣的话可以自己深入学学。其实爬虫是可以赚钱的,大学里可以搞搞兼职
1. 什么是爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。——百度百科
显然这不是我们能看得懂的。简单点说,爬虫就是你写的一个程序,它能帮你在网上爬取你想要的东西,或者是帮你做点重复性的网页工作。百度要实现搜索引擎的功能,就要先用爬虫获取数据。
……那我是不是啥都能爬,包括重要机密那种?
首先,任何网站都有一个
robots.txt,里面描述了网站管理者不希望爬虫做的事,如不要访问某些文件夹、限制访问网站的频率等等。想要查看一个网站的
robots.txt 的话,只需网站的根域名 +
/robots.txt 即可。例如,迷你世界官网的
robots.txt 就在 https://www.mini1.cn/robots.txt
查看。(不过貌似是空的)
其次,网页也有许多的反爬机制以限制爬虫。
我们写的爬虫要遵守
robots.txt,以及限制我们访问的频率。
2. 微编写两个小爬虫
在这之前我先介绍一下 Python 的文件读写操作。
Python 使用 open(dir, mode)
读取文件。其中,dir
为一个文件的绝对路径或相对路径的字符串,mode
决定了打开文件的模式。如果不写这个参数,那默认为只读(r)。下面列出一些常见的
mode 参数:
mode 参数 |
内容 |
|---|---|
r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。文件必须存在,否则会出错。 |
r+ |
打开一个文件用于读写。文件指针将会放在文件的开头。文件必须存在,否则会出错。 |
rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。文件必须存在,否则会出错。 |
rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。文件必须存在,否则会出错。 |
w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
w+ |
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
a+ |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
简单来说,r 读文件,w
写文件,b 用二进制格式打开,可以打开非文本文件。相比于
w,a
为追加,在被多次调用时不会覆盖文件原来的内容。+
可以「拓展功能」,由原来单一的读、写变成同时可读写模式。但
r+ 得保证文件存在。
open() 函数会返回一个 file
对象,而这种对象有个 read()
方法。调用后,会读取文件里的内容(字节),并以字符串的形式返回。比方说,我们让
f = open("mnsj.txt", "r"),如果执行
print(f.read()),那就会输出 mnsj.txt
中的内容了。
读完文件后需要关闭文件,代码为
f.close()。非常多的情况下我们会忘记这一操作,所以另一种方法就是使用
with。对比一下两种写法:
1 | # 第一种 |
推荐使用第二种写法。下面列出了 file 对象的常用方法:
file 对象的方法 |
内容 |
|---|---|
read(size) |
读取 |
close() |
关闭文件。 |
write(content) |
将 content 写入到文件中。 |
下面我们开始写两个小爬虫。
我们使用 Python 来写我们的爬虫代码。我们爬取 迷你世界官网 的源代码:
1 | import requests # 引入 requsets 库 |
成功输出了迷你世界官网的 HTML 代码!有同学会发现,换成某些网站可能会报错。出现这种情况的原因、解决方法与 Request 库的进一步了解我们之后再聊。
接下来是下载图片的爬虫。在网上冲浪时,经常能碰见能够生成随机壁纸的网站以及 API。我们来写一个爬虫把图片下载下来。
1 | import requests |
发现同文件夹下出现了 plmm.jpg 文件。真的有漂亮美眉!
至此,我们对爬虫已经有了初步的了解。下次活动我们会介绍 HTTP 协议和爬虫发送请求的具体过程,虽然非常枯燥,但是非常重要,请一定要认真听。
3. Web 请求过程分析与 HTTPS 协议
在学习 Request 库之前,我们先来了解 Web 请求过程以及 HTTPS 协议。
3.1 Web 请求过程
渲染一个网页有服务器渲染和客户端渲染两种方式。具体过程不做过多介绍。
简单来说,服务器渲染,就是服务端把 HTML
和数据整合在一起发送给客户端;客户端渲染,就是服务端先把 HTML
的「框架」发送给客户端,在客户端再次请求获取数据后,动态地生成网页内容。其中,页面的渲染过程主要由客户端的浏览器完成,因而得名。
什么意思呢?以在百度搜索内容的过程举例。比方说我搜「迷你世界」:
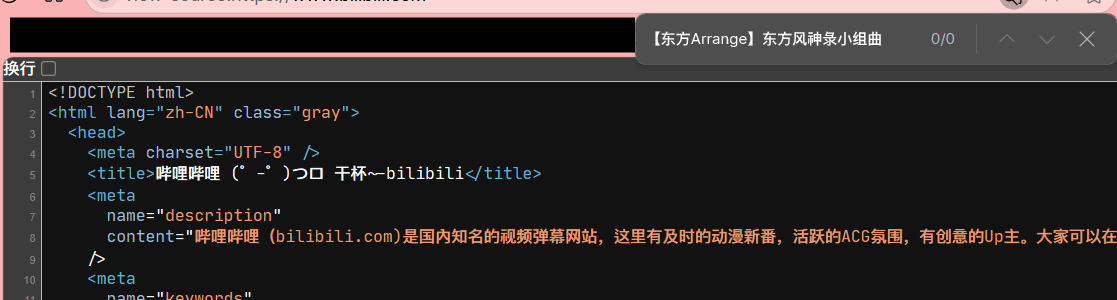
我们 右键 → 查看页面源代码 来查看页面的 HTML 源代码。在其中搜索「迷你世界」,出现了大量匹配。可见,服务器将我们请求关于「迷你世界」的相关数据写进了 HTML 中,再把这个 HTML 返回给了我们。这属于服务器渲染。
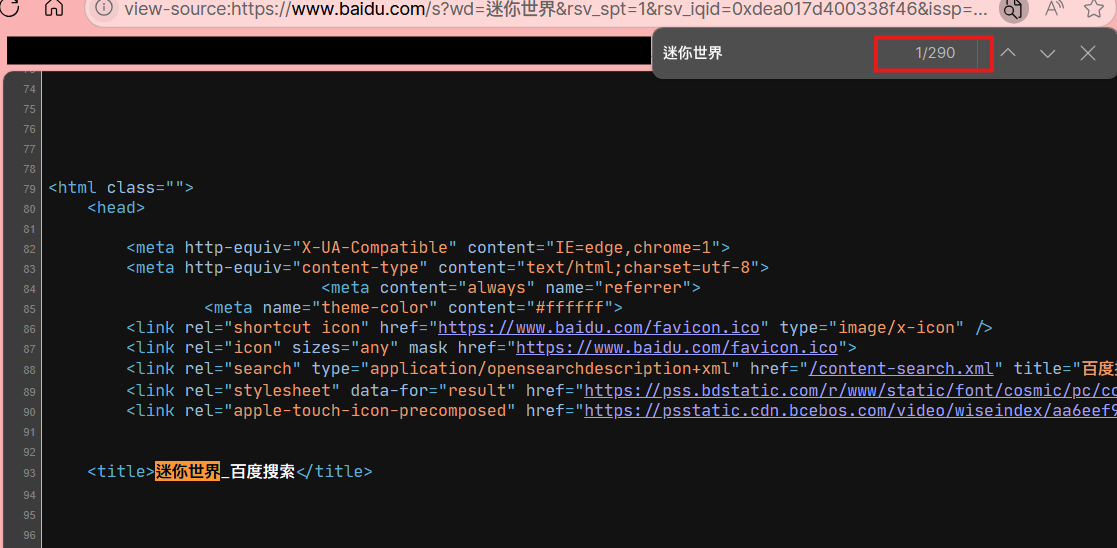
客户端渲染的一个例子是 B 站首页。B 站首页有许多系统推荐的视频,算是客户端索取的数据。然而,我们查看 B 站首页源代码,会发现他空空如也:
这种就属于客户端渲染。
对于第一种情况我们可以直接爬取网页源代码后再处理源代码;但如果我们面对的是第二种情况呢?这就需要我们使用浏览器的抓包工具。按下 F12,选择网络(Network),就可以看到每个网络操作的相关信息,包括详细的耗时数据、HTTP 请求与响应标头和 Cookie。在名称(Name)一栏的第一个就是客户端先收到的 HTML 框架;后面就是客户端陆陆续续渲染的数据了。选择标头(Headers),第一行就是这个数据所在的 URL。
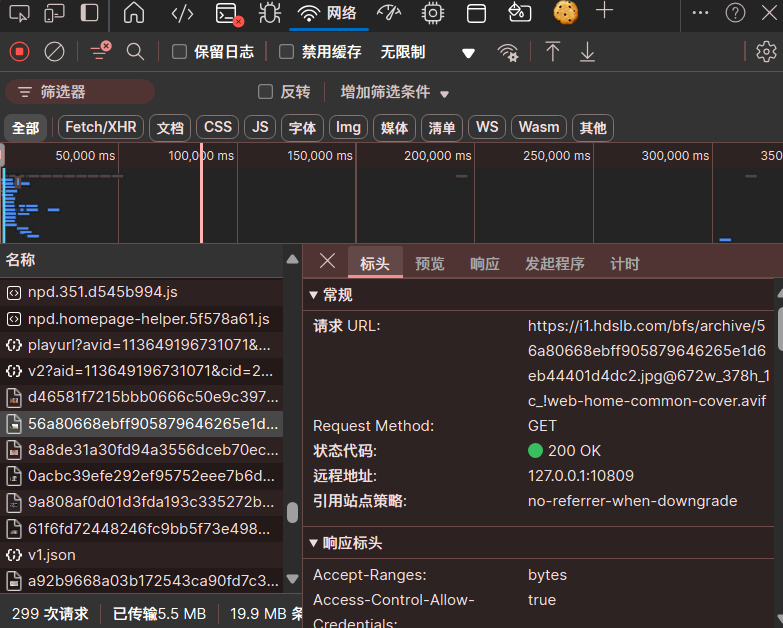
关于 Web 请求过程我们就先讲这么多,主要是了解了解抓包的过程。
3.2 HTTP 协议
HTTP 协议,Hypertext Transfer Protocol(超文本传输协议)的简写。浏览器和服务器间的数据交互遵守的就是HTTP 协议。
通常,由 HTTP 客户端发起一个请求,建立一个到服务器指定端口(默认是 80 端口)的 TCP 连接。HTTP 服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如
HTTP/1.1 200 OK,以及返回的内容,如请求的文件、错误消息、或者其它信息。——维基百科
HTTP 协议的一条消息有请求和相应两种类型。
3.2.1 HTTP 请求
请求消息有三块内容:请求行、请求头、请求体。
请求行包括请求方法、资源路径与协议版本。其中,请求方法我们需要了解两种:GET 方法 和 POST 方法。GET 用于获取数据,如进入一个网页时,获得网页内容;POST 用于创建数据,如用户提交自己的用户名等等。
请求头包含一些给服务器的信息,如 HOST、User-Agent、cookie 等等。User-Agent 表明了客户端的相关信息。
请求体一般放一些请求参数。GET 的请求体一般是空的。
3.2.2 HTTP 响应
响应消息有也三块内容:状态行、响应头、响应体。
状态行有协议版本和状态码。404(Not
Found)就是一种状态码,表明「
服务器无法根据客户端的请求找到资源」。状态码对应的意思(状态信息)可以参考
这里。
响应头包含一些给客户端的信息。如日期、编码类型等。
响应体包含的是客户端真正要的内容,如 HTML 等,也就是我们要爬的东西。
3.2.3 使用浏览器抓包工具查看上述内容
还是按下 F12,选择网络(Network),选择一个数据,就可以看到请求方法、状态代码等诸多内容。
了解了这么多内容,下次我们是时候该学学 requests
这个库咋用了。
4. requests 库入门
4.1 基本方法与函数
在第二节我们展示了这样一段代码:
1 | import requests # 引入 requsets 库 |
但有些人可能会发现如果把网址换成其他的会出现「404」或「异常访问请求」的提示。这又是咋回事呢?别急,在这之前让我们先来了解
requests 的一些基本用法。
使用 requests
库前得先安装一次这个库。直接在命令行(cmd)中输入
pip install requests 即可。如果网速太慢,可使用清华源。输入
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple requests
即可。
在我们导入 requests
库(import requests)后,我们可以用 requests
库下的方法 get 获得一个
response 对象:
1 | import requests # 导入 requests 包 |
该对象包含了具体的响应信息,如状态码、响应头、响应内容等。节选部分如下表格:
| 代码 | 说明 |
|---|---|
response.status_code |
返回 HTTP 的状态码,比如 404 和 200 |
response.content |
HTTP 响应内容的二进制形式 |
response.text |
HTTP 响应内容的字符串形式 |
response.apparent_encoding |
从内容中分析出的响应内容编码方式 |
response.encoding |
从 HTTP header 中猜测的响应内容编码方式 |
response.ok |
检查 status_code 的值,如果小于 400,则返回
True,如果不小于 400,则返回 False |
emm……不像人话。那我们来具体输出一下,看看这都是什么东西。
1 | import requests # 导入 requests 包 |
输出来的内容是这样的:
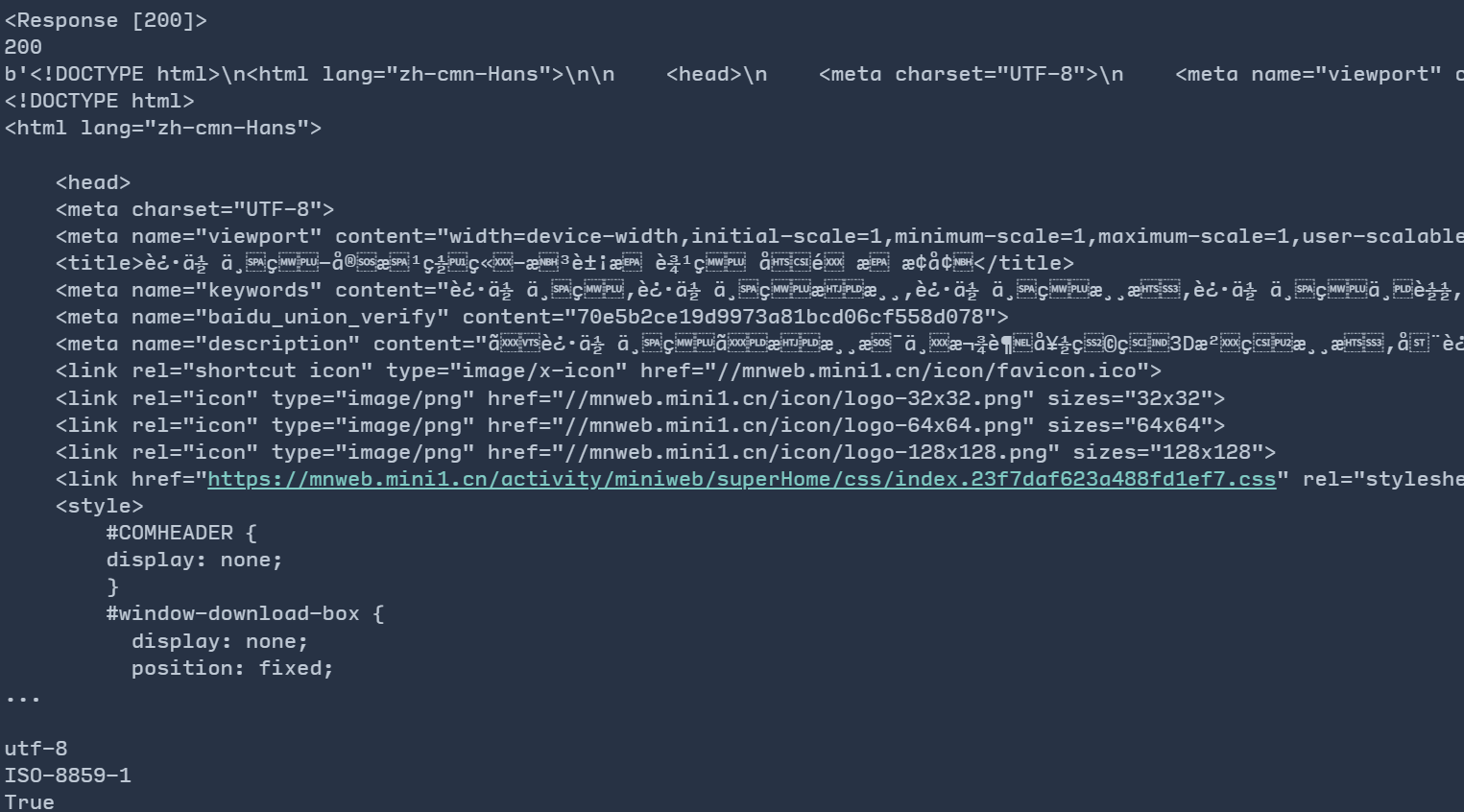
我们一块一块解释。
status_code 表示状态码,200
就代表获取成功了。当然我们也可以使用 ok
来判断自己是否访问成功(即最下面一行的 True
表示成功)。
content
返回的是响应内容的二进制形式。我们可以发现开头有一个 b
字母,还有一些类似 \xe7\x99
的乱码。这是字节字符串的标志。
text 猜测编码方式将
content 内容编码成字符串。如果页面只有 ascii
码,这那么text 和上述的 content
的结果是一样的。但对于其他的文字(比如中文),就会出现乱码现象(即图中的不知名字符),需要编码才能正常显示。那我咋判断网页用的是什么编码方式呢?我们就需要
apparent_encoding 了:
apparent_encoding
会从网页的内容中分析网页编码的方式,比 encoding
更加准确。(encoding 从 HTTP header
中猜测响应内容编码方式。Python 会从 header 中的 charset
提取的编码方式,若 没有 charset 字段则会默认为
ISO-8859-1,这就是图中无法正确解码的原因。)Python 会根据
encoding 中存的内容进行解码。所以可以采用
response.encoding = response.apparent_encoding(当然手动判断并输入是更保险的)。
现在,你能看懂之前展示的两段代码了吗?
4.2 为啥有「404」或「异常访问请求」?
我们还是没有解决这个问题!如爬取知乎首页:
1 | import requests |
怎么返回了 403?这是「服务器拒绝提供请求的资源」的意思!这该如何解决?
上次说到,请求头(header)中的 User-Agent(UA) 表明了客户端的相关信息。服务器就是通过这个判断你是人还是爬虫。这已是最简单的反爬机制。所以说,我们要通过修改 UA 来把自己的浏览器「伪装成人」。
首先,我们获取一个正常点的
UA。通过上回说到的浏览器抓包工具找到了一个正常的 UA:
)
把他复制下来。
get() 中不仅可以传入网址,还可以传入
header,类型为字典。所以,我们要创建一个包含 UA 信息的字典:
1 | headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"} |
就像这样。现在,我们再来试一下:
1 | import requests |
可喜可贺!成功骗过了知乎!这也是我们反反爬的一个技巧。
接下来,请大家尝试一下实现这样一个程序:输入一个游戏名,返回必应搜索到的网页源代码。(如,我输入「原神」,程序返回给我
https://cn.bing.com/search?q=原神 的源代码。)
提示:f-string 用法:
1 | str = 'Miniworld' |
5. 典中典之百度翻译
什么?我只了解了这么点就可以直接上手了?唔,我们分析一下整个翻译的流程:输入翻译内容→点翻译按钮→得到翻译内容。第一步需要我们用
post 方法上传内容,获取翻译结果则需要 get
方法。思路大概理清楚,就可以使用抓包工具去看看我们究竟要获得什么,得到什么啦!大家可以先自己找找。
打开 百度翻译,按 F12
打开抓包工具后,在翻译框中随便输入一个词,以找到
post:
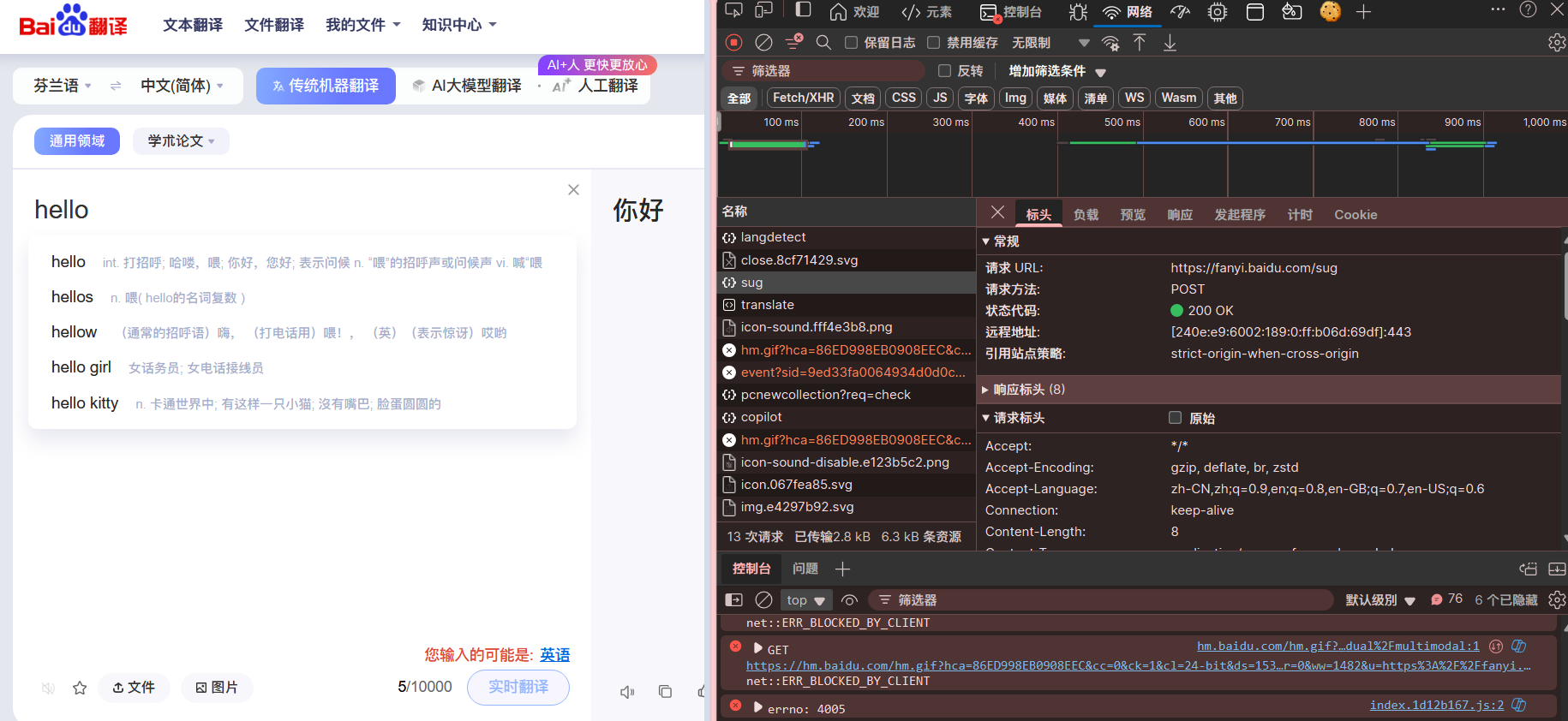
发现其中 sug 的请求方法是
post,且负载里有我们提交的内容,返回的东西也正好是我们想要的。就把这个爬下来吧!
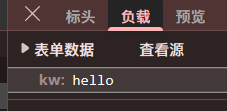
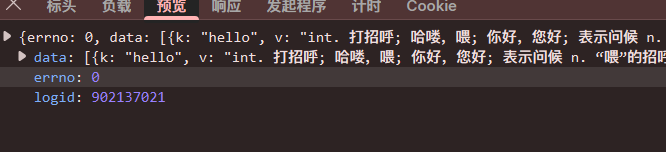
大概介绍一下 request 中 post
的使用方法:
requests.post(url, data={key: value}, args)
其中,url 为请求 url,data 为发送到指定 url
的字典,args 为其他参数,如 cookies
等。负载中,中,kw 为我们要提交的内容,所以我们要建立一个有
kw 的字典。尝试一下!
1 | import requests |
唔,有乱码。观察给我们返回的内容,可以发现他是以 json 的格式返回的。所以我们直接让程序返回 json 数据:
1 | import requests |
这下正常多了,发现直接返回一个字典。让我们把释义输出来吧:
1 | import requests |
大功告成!
有同学会发现,这个简单的小程序只能翻译单词而不能翻译句子——这还需要我们掌握更多的技巧。下一节,我们来介绍一下正则表达式。